China and AI
China x AI Reference List is a 30+ page shared Google doc with up-to-date links and references related to all things China and AI-related. You don’t need to read the rest of this page if you know about this resource.
The best expert on China and AI is Jeffrey Ding, Assistant Professor of Political Science at George Washington University. See his ChinAI substack. Some takeaways:
- China is behind on AI and it’s unclear whether they have a path to “overtake” the US. AI is a complicated subject and it’s not even obvious what it means to “dominate”. Data is an advantage for some things (e.g. facial recognition) but much depends on the kind of application to which you put that data.
- China is far behind on semiconductors and chips, and machine speed is an important factor in deciding who’s “ahead”.
See his Mar 2018 thesis Deciphering China’s AI Dream
See Also
Airstreet: The State of Chinese AI a Jul 2024 summary from an AI venture capital firm.
[podcast] Sihao Huang and China-AI
Researchers originally from China now make up 38 percent of the top A.I. researchers working in the United States, with Americans making up 37 percent, according to the research. Three years earlier, those from China made up 27 percent of top talent working in the United States, compared with 31 percent from the United States.
China’s game plan for the AI race is from the Asymmetric Substack and argues that China is simply using its “bide time” strategy, steadily building its core technologies while waiting for the US to make a mistake.
Chinese grammar detection GrammarGPT Exploring Open-Source LLMs for Native Chinese Grammatical Error Correction with Supervised Fine-Tuning
Alibaba’s Tongyi Qianwen
SenseTime is the world’s largest facial recognition company
Chip Huyen’s 2020 blog post The MLOps race between the US and China
Few American Internet companies have attempted continual learning, and even among these companies, continual learning is used for simple models such as logistic regression. My impression from both talking directly to Chinese companies and talking with people who have worked with companies in both countries is that continual learning is more common in China, and Chinese engineers are more eager to make the jump.
Chip Huyen’s Mar 2024 update
I was under the impression that GitHub wasn’t widely used in China, and my view back then was perhaps colored by China’s 2013 ban on GitHub.
However, this impression is no longer true. There are many, many popular AI repos on GitHub targeting Chinese audiences, such that their descriptions are written in Chinese. There are repos for models developed for Chinese or Chinese + English, such as Qwen, ChatGLM3, Chinese-LLaMA.
While in the US, many research labs have moved away from the RNN architecture for language models, the RNN-based model family RWKV is still popular.
There are also AI engineering tools providing ways to integrate AI models into products popular in China like WeChat, QQ, DingTalk, etc. Many popular prompt engineering tools also have mirrors in Chinese.
Jon Russell summarizes China’s latest AI regulations:
Still, more are launching: JD.com just unveiled a large language model called ChatRhino link. Finally, The New York Times found Baidu’s Ernie bot performed better than ChatGPT in Chinese but, yeah, it dodged sensitive questions
Baidu claims its ERNIE bot is as good as GPT-4. It can generate video and audio responses
2023-05-17: Kissinger on how to avoid WW3
AI will become a key factor in security within five years.
AI cannot be abolished. China and America will therefore need to harness its power militarily to a degree, as a deterrent.
“And if you then rely entirely on what you can achieve through power, you’re likely to destroy the world.”
Chinese LLM
DeepSeek (recap on X)
[!NOTE] Training: - 617B MoE w/ 37B active param - Use MLA, compressing KV and Q to lower dim space to improve inference caching + memory during training - Multi token prediction (MTP) (with depth=1), huge impact (see ablation), especially on GSM8K and HumanEval, I wonder why? - FIM and next token prediction objective - - MoE: - Fine-grained expert with auxiliary loss-free load balancing (adding a bias before the routing). (with ablation). Bias update speed 0.001 and 0 for the last 500B token - Auxiliary loss term to prevent imbalance in the same sequence (alpha=0.0001 (very small impact)) No token dropping - Routing MoE to expert in M=4 different nodes max to have efficient communication - NVLink (intra-node communication) is 3.2x faster than InfiniBand (inter-node communication) so we can have 3.2 experts per node and no extra communication. - - Learning rate schedule (similar to WSD): - 2K step warmup (0 -> 2.2e-4) - 10T constant (2.2e-4 -> 2.2e-4) - 4.3T cosine decay (2.2e-4 -> 2.2e-5) - 333B constant (2.2e-5 -> 2.2e-5) (no smooth decay to 7.3e-6) - 167B constant (7.3e-6 -> 7.3e-6) (no annealing to 0) - - Others hyperparam: - AdamW (beta1=0.9, beta2=0.95) - Gradient clipping = 0.1 - 4K context length (before context extension) - - 469B of batch size scheduling (3072 -> 15360), 15360 * 4K = 61M tokens per batch (holy shit) - MTP loss weight = 0.3 for 10T then 0.1 - - Long context extension: - 4K context window, then 32K, then 128K using Yarn. - same lr as pre-training - Only NIAH test, no HELMET or RULER benchmark :( Infra: - ONLY 2048 H800 TO BUILD A COMPETITOR TO GPT4/SONNET 3.5 IS CRAZY - No TP, only PP, EP, DP, and zero1 - Custom bidirectional PP schedule (store 2 copies of parameters but increase overlap) - Fixed 20SM only for communication (very specific to their cluster) - Recomputation of RMS Norm and Up projection layer - EMA on CPU to have a good estimate of the model without needing to decay - - FP8: - Mixed precision training (see picture), computation done in full precision are: Embedding, output head, gating module for MoE, normalization, attention operators - Mixed precision storage, full precision are: Copy of the weight, weight gradient, optimizer state (bf16 for the latter instead of fp32) - Fine-grained quantization allowing E4M3 FP8 format (see picture) (a lot more info in the paper) - Few FP8 communications, mainly BF16 - E5M6 for activation after attention operator (bc they are used in backward) - - SFT: - Synthetic data from R1 (an internal one, not the public one) - Used RL to finetune R1 model on both (problem, answer) and (system prompt, problem, answer) data R1 expert model now generates (w/ high temp) more comprehensive reasoning data that can be used for SFT - Using both rule-based and model-based reward models to select the data. - Using sample masking, with lr 5e-6 -> 1e-6 - - RLHF: - They used “Group Relative Policy Optimization” for final alignment
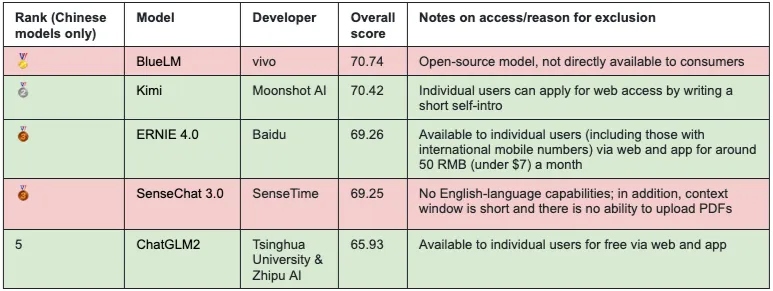
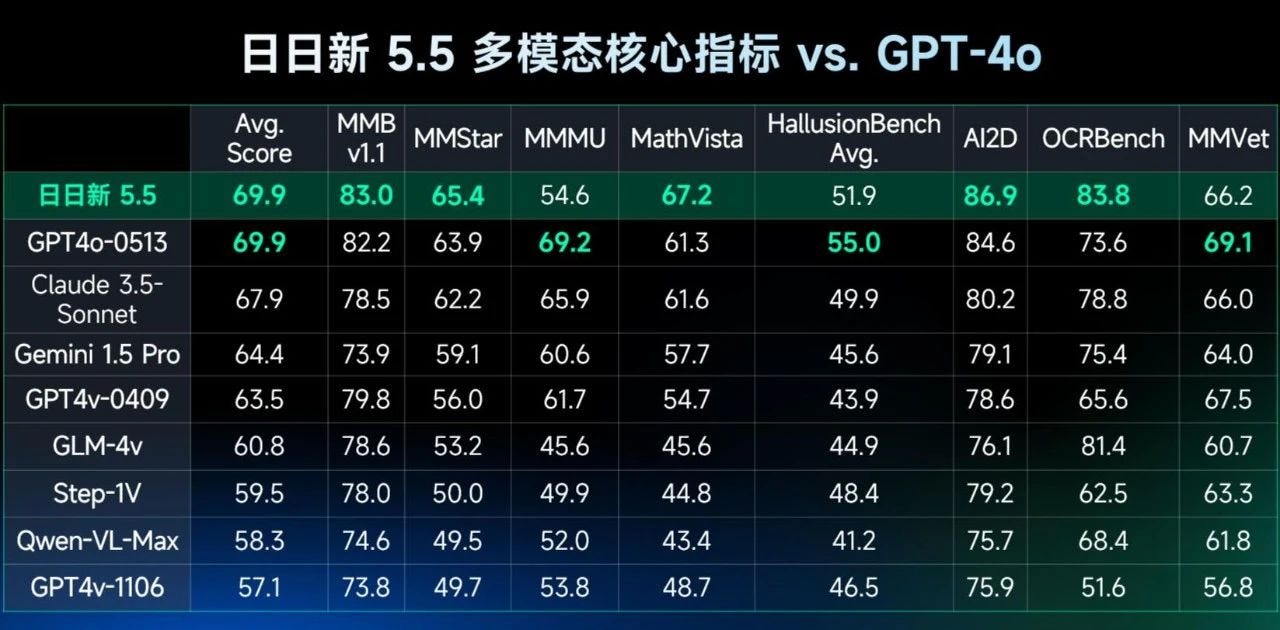
See Paul Triolo ChatGPT and China: How to think about Large Language Models and the generative AI race
01.AI is Kai Fu Lee’s Startup (see HN). The model is Yi Open Source
AI et al. (2024)
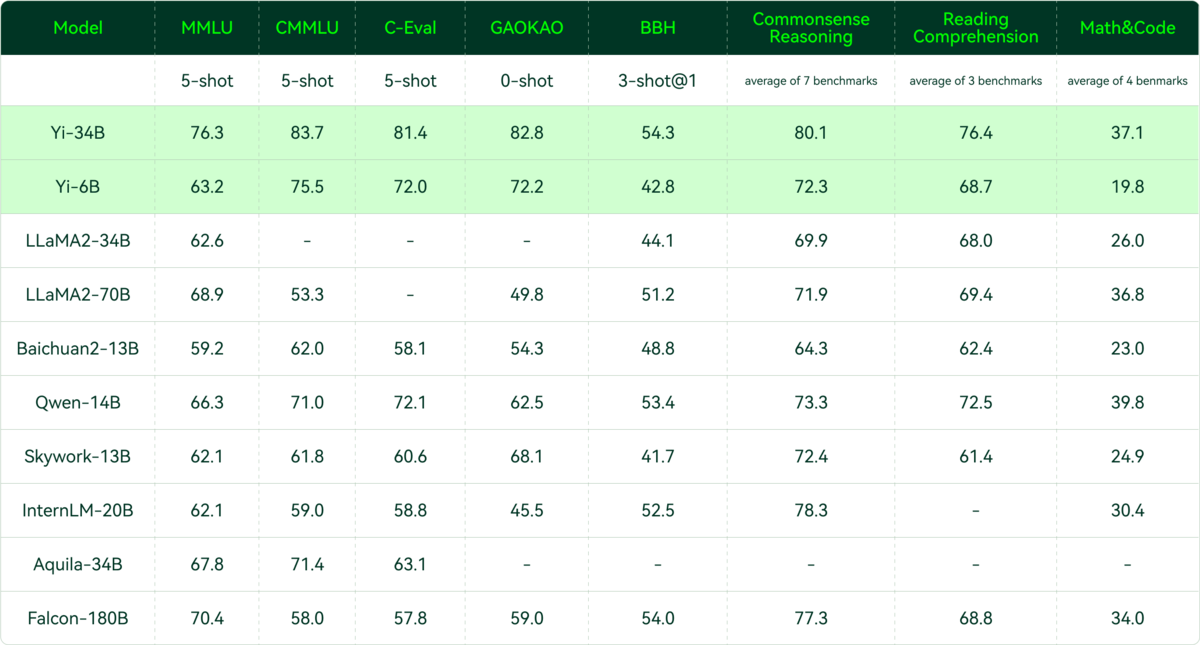
Regulation
A Beijing court has ruled that AI-generated art is copyrightable, the opposite of the US stance. The case involved an image generated by Stable Diffusion.
Jeff Ding made a translation of the Blue Paper Report on Large Model Governance (2023): From Rules to Practice:
To file with the algorithm registry, entities have to give detailed information about their algorithm and include other information such as an algorithm safety self-assessment report
The report also gives examples of Baidu and other companies and their implementation of digital watermarking and other techniques intended to follow the spirit of the algorithmic controls
I haven’t listened to this 30-minute podcast (yet), but Zvi says they “discuss Chinese tech regulations, which she makes clear are very real and having big impacts on Chinese companies and their ability to operate, and the practical issues regulators must solve to do their jobs”:
In AI We Trust talks to Helen Toner, formerly of the OpenAI board, about practical concerns for regulators of technology (they don’t discuss OpenAI).
Matt Sheehan argues in Aug 2024 that, partly because of ChatGPT, officials and regulators are taking “AI Risk” more seriously
China’s AI Regulations and How They Get Made: A review of a Dec 2022 report1by Matt Sheehan, a fellow at the Carnegie Endowment for International Peace, on China’s AI regulatory process.
“China’s approach to AI governance has been uniquely focused on algorithms” as opposed to regulating training data, compute or the ultimate actions taken or enabled by an AI product. This choice, Sheehan argues, is “clearly displayed in Chinese policy discourse around regulations and the decision to make algorithms the fundamental unit for transparency and disclosure via the algorithm registry.”
see Experts react to China’s draft Measures governing AI-generated content services:
Providers must “ensure the data’s veracity, accuracy, objectivity, and diversity”, a very high bar given the way LLMs work.
- API providers are responsible for all content their APIs produce!
- Measures apply to research as well as to products
- Must apply to the CAC for a security assessment before making it available to the public.
- Must allow tagging, to allow tracing content that was AI generated
AI-generated content (AIGC) must comply with “socialist core values”.
Remember, censorship is extra hard for LLMs because, even if you only train on clean censored data, you won’t know how to respond to user input – which may include data that you want to censor. To understand what you should censor requires training on some censored data.
China already has an “algorithm filing system” (算法备案系统 aka the Internet Information Service Algorithm Filing Systems ) that requires developers to conduct security assessments and disclose details about how their algorithms were trained.
cybersecurity company QiAnXin offers consulting services and tools to help with compliance
Saad Siddiqui is an AI governance researcher who writes Comparisons between China and other countries on AI Safety
First results from CAICT’s Safety Benchmark is a Jeff Ding summary of China Academy of Information and Communications Technology’s (CAICT) large-model safety benchmarks, summarized in three categories: technology ethics, data security, and content security, which includes:
- Sensitive politics
- Major national policies
- Core values
- Territorial sovereignty issues
- Major historical issues
- Religious issues
Implications
China’s technology is likely to evolve in a more vertical manner, rather than the general-purpose chatbot of the US. Your personal robot might be able to respond to your commands but it just won’t be of much use to somebody who wants to talk about politics.
Wired says China is investing heavily in autonomous warfare (drones, robots, etc.)
A report out of Georgetown University in 2021 found that the People’s Liberation Army spends more than $1.6 billion on the technology each year—roughly on par with the US.
China and Medical AI
See Jeff Ding’s summary of an Aug 2023 AI Medical event:
asked if medical care would be the first batch of industries where GPT lands, Dalei Zhang founder of Airdoc[鹰瞳科技], responded: “Medical care is not the first batch, it is the zeroth batch.”
and
According to VBData estimates, from 2020 to 2025, the compound annual growth rate of China’s medical AI sector will be about 40%, and the total market size will exceed 30 billion RMB by 2025.
(Full Translation (Google Doc))
Chinese Hardware
Why Huawei’s 7nm is not that impressive and why it’ll be 20 years till China has world class lithography: The Internet reports that Tsinghua has broken through the lithography technology chokehold
Within 20 years, it is impossible for any country in the world to be able to completely independently build a lithography machine that represents the most advanced level in the world, and the United States is no exception.
Meanwhile, Nvidia is on track to sell $12B worth of its chips in China (2024), double its competitor Huawei and bigger than Nvidia’s entire graphics and gaming business last year.
It seems inevitable that Huawei will become more competitive soon, but still big Chinese tech firms opt for Nvidia. Tencent just last week announced a 20% improvement with its LLM training thanks to adopting Nvidia tech, while a top Huawei exec has denied that a chip shortage will impact China’s AI development.
But it isn’t just about China-tailored chips, we’ve noted before that there are loopholes and the Wall Street Journal looked into the “underground network” that’s sneaking Nvidia chips into China—including using luggage from students returning home.
China’s Research
Also see The Geography of Retracted Papers for look at how much fraudulent research happens in China.
Analyst Wendy Chang says China keeps generative AI on simmer
The cyberspace administration has since released its own set of approved LLM training data. Influential technical working group TC260 provided additional, stringent and remarkably detailed standards on input training data and the output of a model. Notably, development based on unregistered foundational models is explicitly forbidden, so foreign open-source models cannot be used. While large tech companies often actively help shape these standards, compliance could still be very costly for them. Smaller companies or entrepreneurs could well be discouraged from venturing into this space.
Chinese AI Entrepreneurs
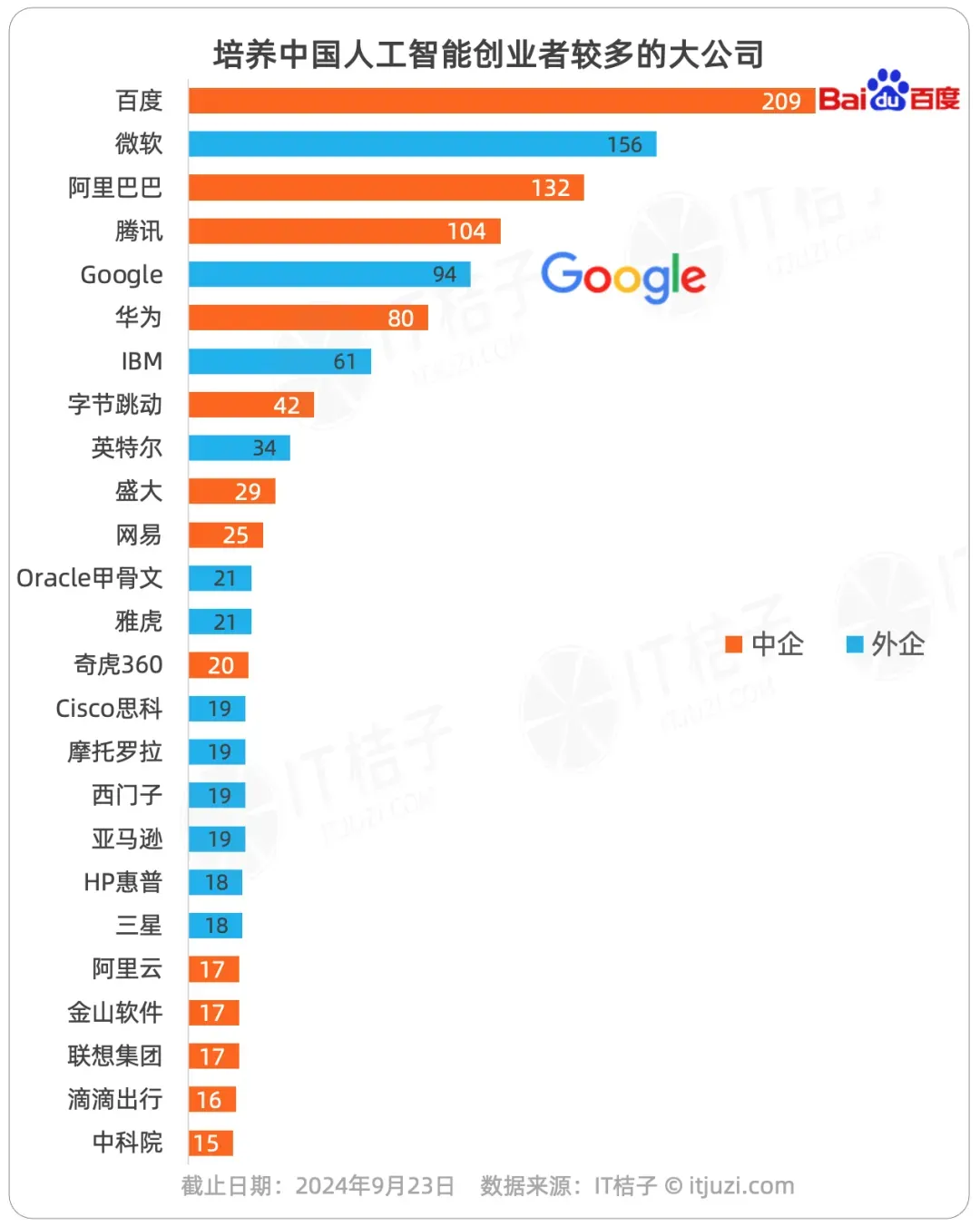
ChinAI Newsletter points out that “12 of the top 25 previous employers of Chinese AI entrepreneurs are foreign companies (in order from top down: Microsoft, Google, IBM, Intel, Oracle, Yahoo, Cisco, Motorola, Siemens, Amazon, HP, Samsung). The blue-shaded bars are foreign companies, while the orange-shaded bars are Chinese companies.”
Other
China blocks access to HuggingFace.
Georgetown Center for Security and Emerging Technology publishes Translation Snapshot: Chinese AI White Papers : a collection of translations of recent government-authorized reports about Chinese AI.
also see Kissinger on China and AI
A big winner in the backlash against China might be Japan, which is rapidly expanding its semiconductor industry.
Beijing Cultural Review’s “AI: More than just a Technological Revolution” Issue
Summary: This influential Chinese bimonthly magazine offers high-quality commentary on a wide range of topics, including AI. They recently did a recap of their previous four issues, and the April one was dedicated to AI. Article topics included: the concentration of AI power in a few tech giants, the geopolitical logic of data center expansion, and how workers’ organizations can adapt to generative AI.
Source: 文化纵横 (Beijing Cultural Review) — A previous ChinAI issue (#167) translated their article about the re-skilling of migrant workers in the context of China’s digital transformation.
References
Footnotes
What China’s Algorithm Registry Reveals about AI Governance at Carnegie Endowment↩︎